Learning to Regress Bodies from Images using Differentiable Semantic Rendering
Sai Kumar Dwivedi1, Nikos Athanasiou1, Muhammed Kocabas1,2, Michael J. Black1
1Max Planck Institute for Intelligent Systems, Tuebingen, 2ETH Zurich
ICCV2021

A state-of-the-art approach (purple) fails to estimate accurate 3D pose and shape for in-the-wild scenarios. We address this by exploiting the clothing semantics of the human body. Our approach, DSR, (blue) captures more accurate 3D pose and shape.
Abstract
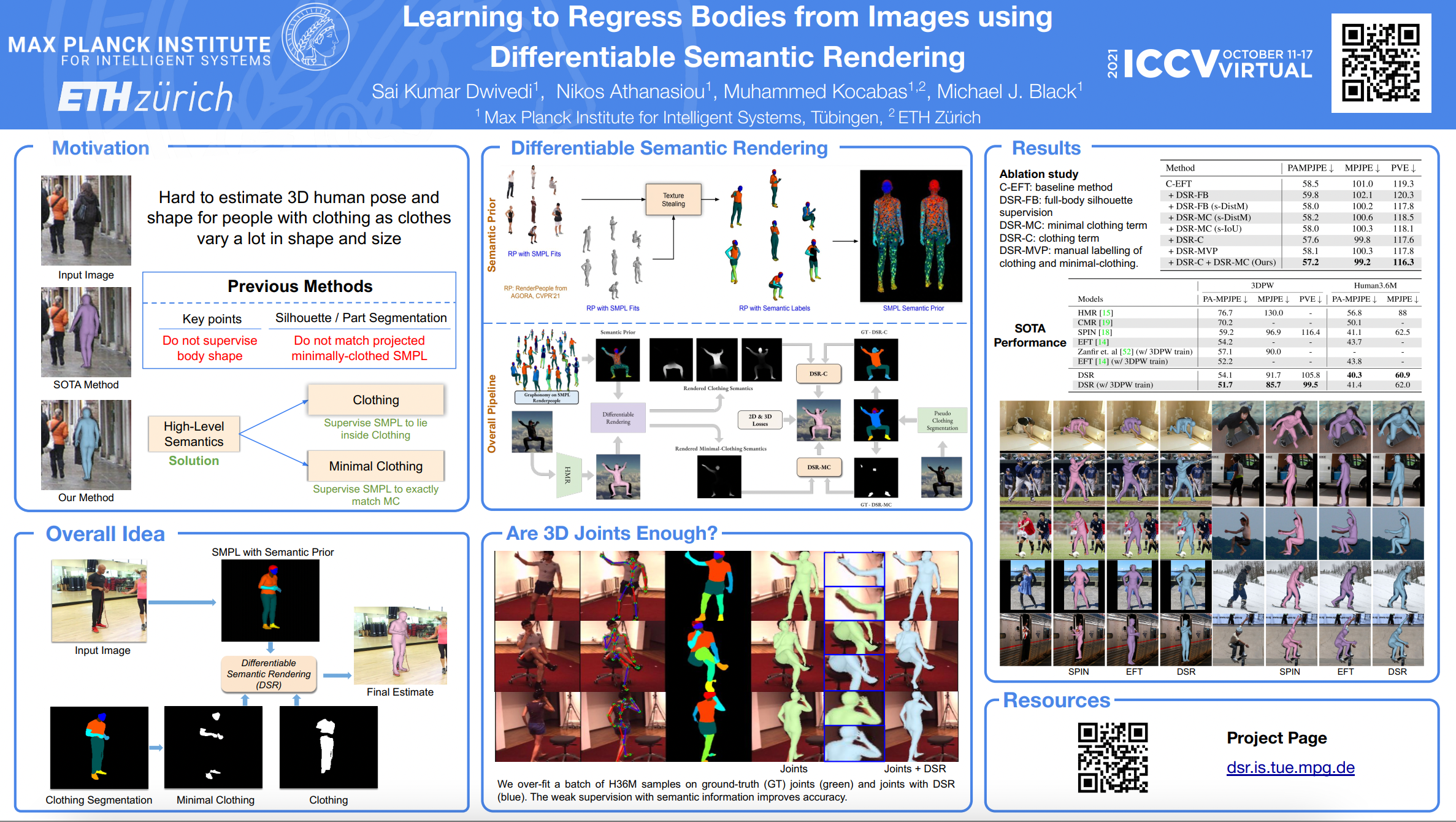
Learning to regress 3D human body shape and pose (e.g. ~ SMPL parameters) from monocular images typically exploits losses on 2D keypoints, silhouettes, and/or part-segmentation when 3D training data is not available. Such losses, however, are limited because 2D keypoints do not supervise body shape and segmentations of people in clothing do not match projected minimally-clothed SMPL shapes. To exploit richer image information about clothed people, we introduce higher-level semantic information about clothing to penalize clothed and non-clothed regions of the image differently. To do so, we train a body regressor using a novel ‘’Differentiable Semantic Rendering - DSR" loss. For Minimally-Clothed regions, we define the DSR-MC loss, which encourages a tight match between a rendered SMPL body and the minimally-clothed regions of the image. For clothed regions, we define the DSR-C loss to encourage the rendered SMPL body to be inside the clothing mask. To ensure end-to-end differentiable training, we learn a semantic clothing prior for SMPL vertices from thousands of clothed human scans. We perform extensive qualitative and quantitative experiments to evaluate the role of clothing semantics on the accuracy of 3D human body estimation. We outperform all previous state-of-the-art methods on 3DPW and Human3.6M and obtain on par results on MPI-INF-3DHP.
Method

Method: For more accurate human body estimation, we supervise 3D body regression training with clothed and minimal-clothed regions differently using our novel DSR loss and the semantic prior. The semantic prior represents a distribution over possible clothing labels for each vertex.
Results

Qualitative Results: The mesh in purple is from EFT and one in blue is our DSR method. Our method accurately estimates the 3D human shape and pose and out-performs state-of-the art method in case of loose clothing.
Video
Paper


Poster
Code and Pretrained Model

https://github.com/saidwivedi/DSR
Bibtex
@inproceedings{Dwivedi_DSR_2021, title = {Learning To Regress Bodies From Images Using Differentiable Semantic Rendering}, author = {Dwivedi, Sai Kumar and Athanasiou, Nikos and Kocabas, Muhammed and Black, Michael J.}, booktitle = {Proc. International Conference on Computer Vision (ICCV)}, pages = {11250--11259}, month = oct, year = {2021}, doi = {}, month_numeric = {10} }